����������ɽ�����Ϸ���3D��������ϷAI���Ի�������
���2016��AlphaGo����֮�̶�����䣬�Ǽʡ�Dota2�������˿ˡ��齫��̱�AI���ˡ�����OpenAI Five��AlphaStarѪϴ���ݾ���������Ϸ�����ƺ��Ѿ���AI��ȫ���£�����Ŀǰ����������������δ����� ��һ�ǻ����ĸ��Ӷ����⡣������Ϸ��Ϊ���ھ��������������
���2016��AlphaGo����֮�̶�����䣬�Ǽʡ�Dota2�������˿ˡ��齫��̱�AI���ˡ�����OpenAI Five��AlphaStarѪϴ���ݾ���������Ϸ�����ƺ��Ѿ���AI��ȫ���£�����Ŀǰ����������������δ����� ��һ�ǻ����ĸ��Ӷ����⡣������Ϸ��Ϊ���ھ��������������

����2016��AlphaGo����֮�̶�����䣬�Ǽʡ�Dota2�������˿ˡ��齫��̱�AI���ˡ�����OpenAI Five��AlphaStarѪϴ���ݾ���������Ϸ�����ƺ��Ѿ���AI��ȫ���£�����Ŀǰ����������������δ�����
������һ�ǻ����ĸ��Ӷ����⡣������Ϸ��Ϊ���ھ�������������������������������ʵ����ķ���ģ�⡣���ǣ�ĿǰAI�ѹ��˵���Ϸ������������2D�ռ��ڡ���ʹ��3D�ռ��DeepMind����֮��3 AI��Ҳ�ǻ�������������Ϸ�ںˣ���ͼ�������������١��������ϷAI�����ܷ�Ǩ�Ƶ���ʵ�����Ǵ��ɵġ�
���������AI�����˶����⡣���е���ϷAI��Ҫ�Ծ���ΪĿ�ģ�����ߵ�ʤ�ʺͶ�λ�����ӿ����̺���ҵĽǶȣ�AI����ֻ��ԽǿԽ�ã���Ҫ��Խ�����Խ�á��������ϷΪ�������д���д����AI�Ϳ���������ѹ���࣬��˭������ûȤ��һ��������ͷ��AI��ս�أ�
���������������㣬������Ϊ�����и���3D������Ҫ��������ߵ�3D��������Ϸ����ΪAI����һ����ս��
��������ɽ���з��е�ս��������Ϸ����ҫ֮�����У����ǿ�������Ϊ���Ի���������AI�����߱��˸���3D������֪����������/ʹ�á���ս���Ŷ���ϵ�ȫ��λ��������
���������жิ��
��������ҫ֮��������ɽ�������з�����һ����������ս��������Ϸ����Ϸ����ʱ������ȵġ��Լ����淨���������ͨ��������½�ϵĴ���ɱ����ʤ�ߡ�
������Ϊһ��3D��Ϸ�����Ӷ����һ��2D��Ϸ�Ѿ�����һ��̨�ף����Լ�����Ϸ�ij����ͼ������ͬ�ֵ�Ҫ���ֽ�һ�������˼����Ѷȡ�
������������˵��AI��Ҫ��������ս������
����1��ʵʱ���볤����
������Ҳ���Ҫ����ʵʱ�IJ������ߣ���Ҫ�������ڵĹ滮���ߣ�ƽ�������ߡ�Ϊ�����ջ�ʤ��������Ϸͨ����Ҫ����30�������ϣ���Ӧ�ľ��߲�����7000�����ϡ�
����2����������Ϣ
������3D��Ϸ�У����ֻ�ܿ���һ���ӽǷ�Χ�ڵ���Ϣ���������������ϰ����ڵ�ס����Ϣ����ˣ������Ҫ��Ч̽�����ɼ�����Ϣ�����߱�����������
����3�����ӵ�״̬�ռ�
����3D������2D���������������Ϣ���������ȵĸ��ӿռ�ṹ���Ӵ�ĵ�ͼ��10����*10������ڶ����ң�100�ˣ����ḻ��Ԫ�أ������������ϰ������ʵȣ����Ի�����֪��̽������˾���ս��
����4�����ӵĶ����ռ�
���������Ҫͬʱ�����ƶ������ӽǷ���������̬��վ���ס�ſ��������������ʰȡ����ҩ����������һϵ�в������������ӵ���϶����ռ䡣���ǹ�����ɢ����Ŀ��ж���������10^7�����������
����5��ս����ս��
���������Ҫ��˲Ϣ���Ļ����;�����������ȷ���жϣ���ȡ�ḻ��ս�Ժ�ս������������ڻ�����ǹ�ߡ����㡢����Ȧ�����̾�Ԯ�ȵȡ�
����6�����˲���
������Ҳ�����Ҫ����ѽ������еĺ�����ͨ�ţ�����Ҫ��������������Դ�Ѽ�����װ����ʱ���жԿ��������˲�����ȣ����˲��ĵ��������Ӹ��Ӷ�䡣
����������Щ�ѵ�Ҳ�ǵ�����Ϊ��AI�������������ӡ����˲�������Ҫԭ��
���������ڱ��ε��о��۽���һ������Ծ֣�mini-game��������230��*230�����ϡ�ʱ��6�����ڡ����2V2�����մ���һ����ʤ������Щ�����⣬������ϷԪ����������Ϸ��ȫ��ͬ��
��������ʵ��·��
�������Ի����������������ǿ��ѧϰ���������㿪ʼ��ͨ���뻷���Ľ������Դ���ѧ��۲����硢ִ�ж����������뾺�����ԡ�AIû��ʹ���κ�������ҵĶ�ս���ݣ���ȫ�������Ҷ�ս��self-play���ķ�ʽ����ѧϰ��
����AI�۲��״̬��Ϣ�������/���ʵ�ʵ����Ϣ�����ͼ���״�ͼ��С��ͼ���Լ���۱�����Ϣ��������һ����AI�۲��״̬�Ƿ������ġ�����ֻ�ܿ���һ���ӽǷ�Χ�ڵ���Ϣ����������Ұ����DZ��ϰ����ڵ�ס����Ϣ��
������ֱ����RGBͼ����Ϊ������ȣ��������ķ�ʽʡȥ��ͼ��Ŀ�����ʶ��Ĺ��̣�רע��AI�ľ��߹��̡����⣬�״�ͼ��С��ͼ�൱���Զ���ʻ�еĸ߾��ȵ�ͼ�����ͼ�൱������������������Ϣ��
����AI�Ķ��������Ϊ�ƶ�����ˮƽ/��������������̬������ʰȡ/ʹ�á������л���������������������ͬʱִ�У��γɾ�ĸ��϶����ռ䡣��������ڲ���ʱ������ڷ�Ӧʱ������ƣ�APM��ÿ���Ӳ���������Ҳ�������ޡ�
����Ϊ����������Ҳ���һ�£����Ƕ�AIҲ��������Ӧ���ơ����ǵ����紫����ʱ��������ȡ��ģ��Ԥ��ĺ�ʱ��AI�ӡ��۲1֡״̬����������1�ζ�������Ҫ120ms����ʱ���ڴ˻����ϣ�����������������100ms��ʱ��ͬʱ��AIÿ�����ִ��4�ζ�����ÿ��������3��������
����ÿ��AI��һ�����������ģ�ͣ�����״̬��Ϣ�����Ԥ��Ķ���ָ�����ͨ��Transformerģ�ʹ�����ҡ����ʵ�ʵ����Ϣ��ͨ��ResNet�������ͼ���״�ͼ��С��ͼ��ͼ����Ϣ��ͨ��MLPģ�ʹ�����۱�����Ϣ��Ȼ��ͨ��LSTMģ��ʵ�ּ���������
����Ϊʵ�ֶ���������������Dz����˷ֲ�ʽ�IJ������������ʽ�ļ�ֵ���磬�������˲�������֮���ͨ�Ż��ơ�
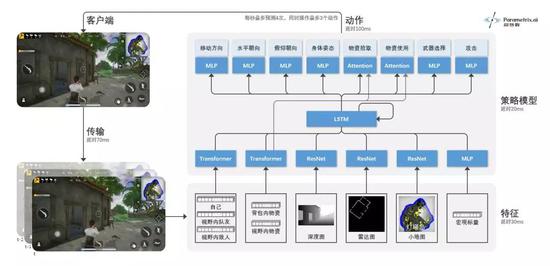 AIģ�ͽṹʾ��ͼ
AIģ�ͽṹʾ��ͼ
�������Ի���������ѵ���ڳ��������е�ͨ�÷ֲ�ʽǿ��ѧϰ����Delta�Ͻ��С�������ͨ����������CPU��Դ����ѵ�����ݣ�ͨ��GPU��Դ����������ģ�Ͳ��������ҿ���ͨ�����������AI��ѵ�����̡��ڸ���Ŀ�У����Ի�������ѵ��һ���൱��������Ҵ���10���ꡣ��������Բ������κι������ϣ�Ŀǰ�Ѿ�֧���˶����Ϸ��AIѵ����
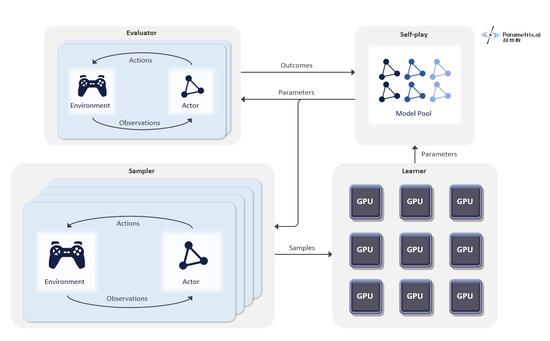 �ֲ�ʽǿ��ѧϰ����Delta�ܹ�ʾ��ͼ
�ֲ�ʽǿ��ѧϰ����Delta�ܹ�ʾ��ͼ
Ŀǰ�ﵽ��Ч��
�������ǿ������Ի����������㿪ʼ��ѧ������3D���������������ȫ��λ������
- 2019LOLȫ������������Ϸ���ϲɷ�TheShy2019��12��15��
- 2019LOLȫ������������Ϸ���ϲɷ�Uzi2019��12��15��
- Jam CityѺעIP��Ϸ ���ʿ�������Ƴ��������Ρ���ѩ��Ե̽�ա�������ǰ102019��12��08��
- �������ȷ桷�����ը����ҡ� ���Ͼ���ץ���������������2019��11��29��
- GDES�����š�2019|��ɽ����Ӫ�ܼ�Ҧ�����羺��ҵ����������ϸ���г���̽��2019��11��24��
- GDES�����š�2019|�Ի���ɽ����Ӫ�ܼ�Ҧ����Ϊ������3����������ȫ��RPG��羺����2019��11��24��
 2017��ҳ��Ϸ�������ݱ��棨2.13��2.19��
2017��ҳ��Ϸ�������ݱ��棨2.13��2.19����һ����ҳ��Ϸ�������� ������������ҳ��Ϸ��������...
- ����֮�˽Կ��ã����ŷ��������Ρ����뽣��11
- �ഺ��ȼ���� QQ��Ϸ��ȭ��97��������K��O
- 56����ҫ�����dz�����������ǿ����һ����λ
- MMORPG�����������ǿվ��顷���ڶ���˹
- PAX������������������ߵľ�Ȼ������������˫��
- ���Ӣ�����������˾������� CEO�����ڵijԼ���
- �����ı�ɱ��������RPG���Ρ�OVERHIT������
- ����IJ���ֵ�㡰DZ��������ƽ̨
- ����С��������Ѷ������ǡ����Σ�������¹��һ
- QQС��Ϸ��Ӫ�����˲��������������QQС��Ϸƽ
- Steam������ٽ��� 2019���ܳ��Ӿ��������
- ��ζͯ����Ȥ����Ѫ�������������¾������
- ��������ӡ�ߡ���������½�ɫ��δ����
- ����ħ���ж���Ѫ����������20�죬�����˷�����
- �ҽ�MT2����������µ�������˭?
- ������ܿ�ȸ������ô�ۼ�����?
- TGA 2019����LOL������ģʽ���� �غ��ƽ�ɫ����
- LOL�ƶ�֮��9.24������������ô�� ���ؾ綾����
- ��ƽ��ӢPEL������11�� SDR���µ�11������


- �������������ư桶��ɽ��ӭ������beta ��������
- �����:ԭ��2��ʵ��濪��Ԥ�� ��52ҳȫ����Ϸָ
- ����Ԫ1800����DLC������������PC ���忪�����
- ���ţ�С����������������̸�������ž��롷
- ɼ�����壺������ð��2��56Ԫ��쭿ᳵ��2��1��
- ��ʹ���ٻ�16���ִ�ս�����´��ͼ���ۿڡ���ʾ
- ��Stadia����Ϸ����22�� �����ջ���15��������
- ������ǰ�ߣ��ƻ��봴�졷���⣺����ս�� ��ս��
- ���������ˣ����硷��ԭ��2����Ѹ���12��5����
- ������eShop�����̵꿪��������� �����Ϸ���
������Ϸ�Ҹ� ���Ʋ�����Ϸ���ܾ�������Ϸ��ע�����ұ����������ϵ���ƭ �ʶ���Ϸ���ԣ�������Ϸ��������������ʱ�䣬���ܽ�������
- ��Ʒ��Ȩ���������У�����������ַ������İ�Ȩ�������Ÿ�֪����վ����������������ɾ��
- ��ʾ����վΪ��ֹ�������ݳ��֣��û����������ۼ��ϴ���Ϸ�豾վ��˺������ʾ������лл